一文带你上手 AI Agent 编程
Archive 说明:这篇主要是 2025 年 3 月左右学习和实践 AI Agent 编程时整理的资料,只适合作为阶段性 archive 回看。今天再看,重点已经不只是“怎么写一个 agent”,而是更偏 harness engineering:为模型提供可验证的上下文、工具、运行环境、权限边界、trace、eval 和回放能力。文中的 API、MCP、CodeAgent 等内容请按当时实践背景理解,不当作最新落地指南。
本文的目标:先用足够的背景解释 LLM、Prompt、Chat Template、Function Calling、MCP 等关键概念,再把这些概念落到一个简单的 DeepSearch Agent,帮助你理解 Agent runtime 到底在做什么。
LLM 基础
Reference:
Andrej Karpathy: https://www.youtube.com/watch?v=7xTGNNLPyMI
3blue1brown: https://www.youtube.com/watch?v=wjZofJX0v4M
High level 的讲一下 LLM 的相关感性概念,目的是对 agent framework 设计的理解产生帮助。
笔者只是以前读书的时候浅跑过一些代码,以及看了一些文章视频学了基本感性认知,如有说的不正确的地方,请大方指正。本节的目的主要是对 Agent 的设计补充一些背景。
Machine Learning Background
机器学习是一种数据驱动的学问,模型可以通过数据不断更新自己的权重,通过计算,预测出某个输出。
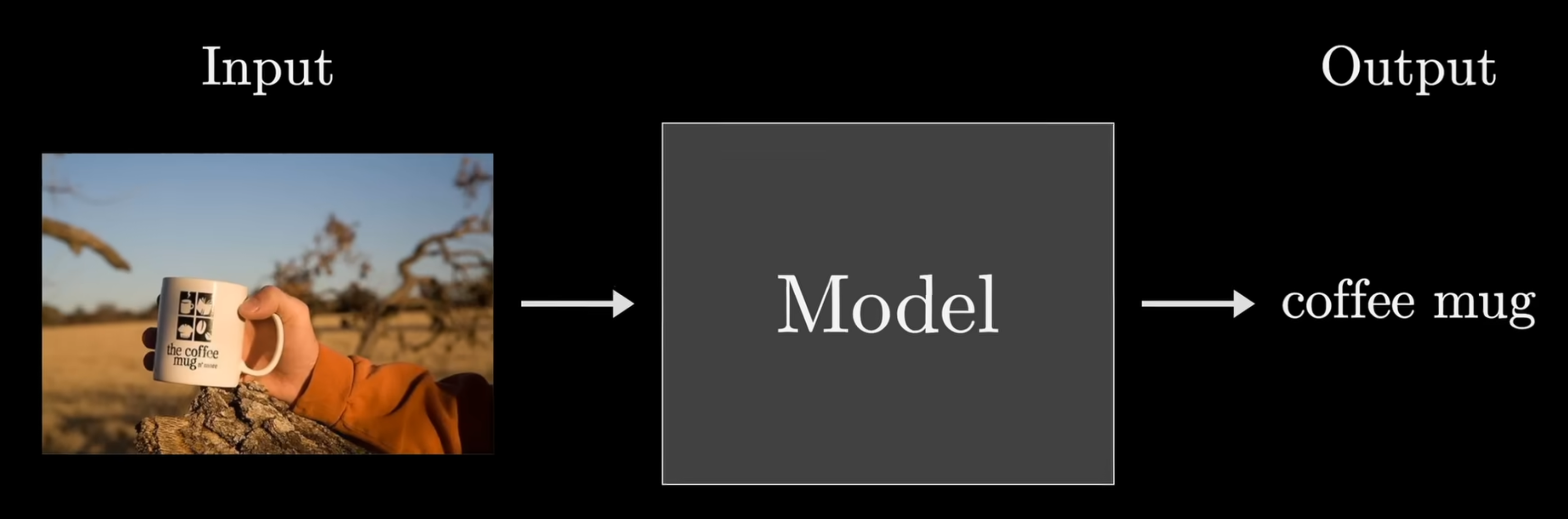
与一般编程思维(函数式编程、结构化编程、面向对象编程,Clean Code 里面讲这三种是最基本的思想)不同的是,机器学习并不指定具体的操作步骤,而是提供一个包含可调整参数的计算架构。通过大量的训练数据(在有监督学习中,这些数据包括输入和对应的输出;在无监督学习中,则只有输入),模型通过调整参数来学习输入与输出之间的关系或模式。
我们常说的参数、权重(weights)是什么呢,比如 DeepSeek R1 671B,llama3.2 70B,权重是训练的时候获得,决定了模型的行为。
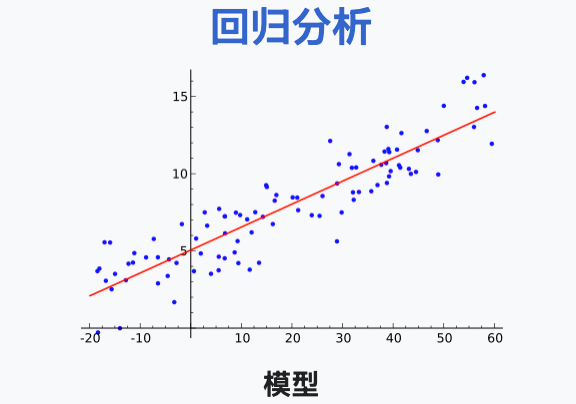
用线性模型举个简单的例子,权重是特征对应的系数(如 y = w₁x₁ + w₂x₂ + b 中的 w₁, w₂ 和偏置 b) 找到这个数据的规律就是不断去修正所有的点到这条线的偏值最小的一处,回归到均值。
大模型有特别多的参数,简单理解为参数越多,他能学习到的模式越多。
但是也不是越多越好,如果数据集不足,或者模型结构不正确,或者训练时间过长,模型对某一方面的特征学习到更多的细节,可能过拟合,对当前数据集的拟合程度过深,泛化性差。
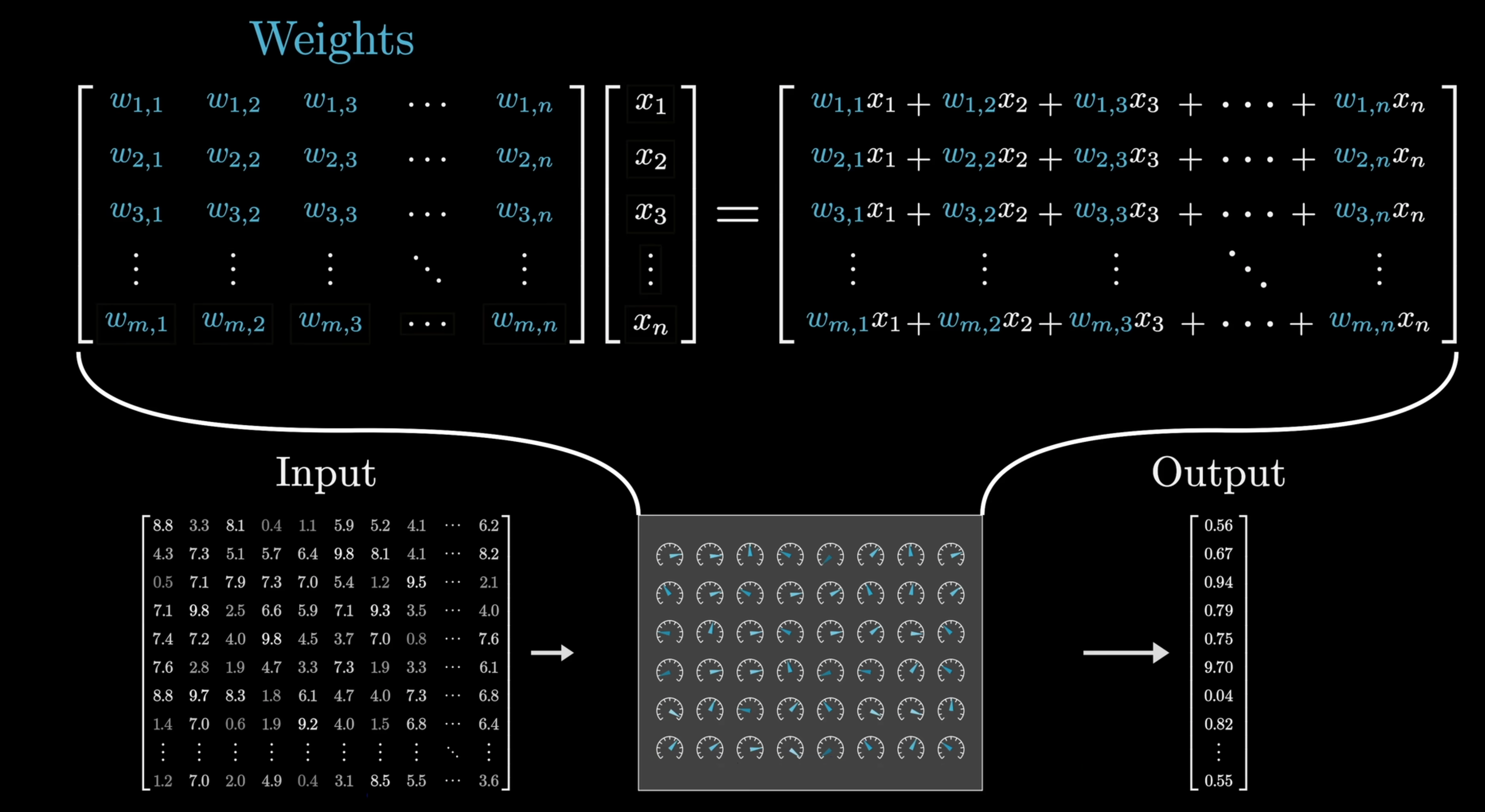

每个参数会变成不同作用的矩阵,用于不同作用的任务,比如 Embedding, Attention 的 (Key、Query、Value、Output 层) 等。
Prediction
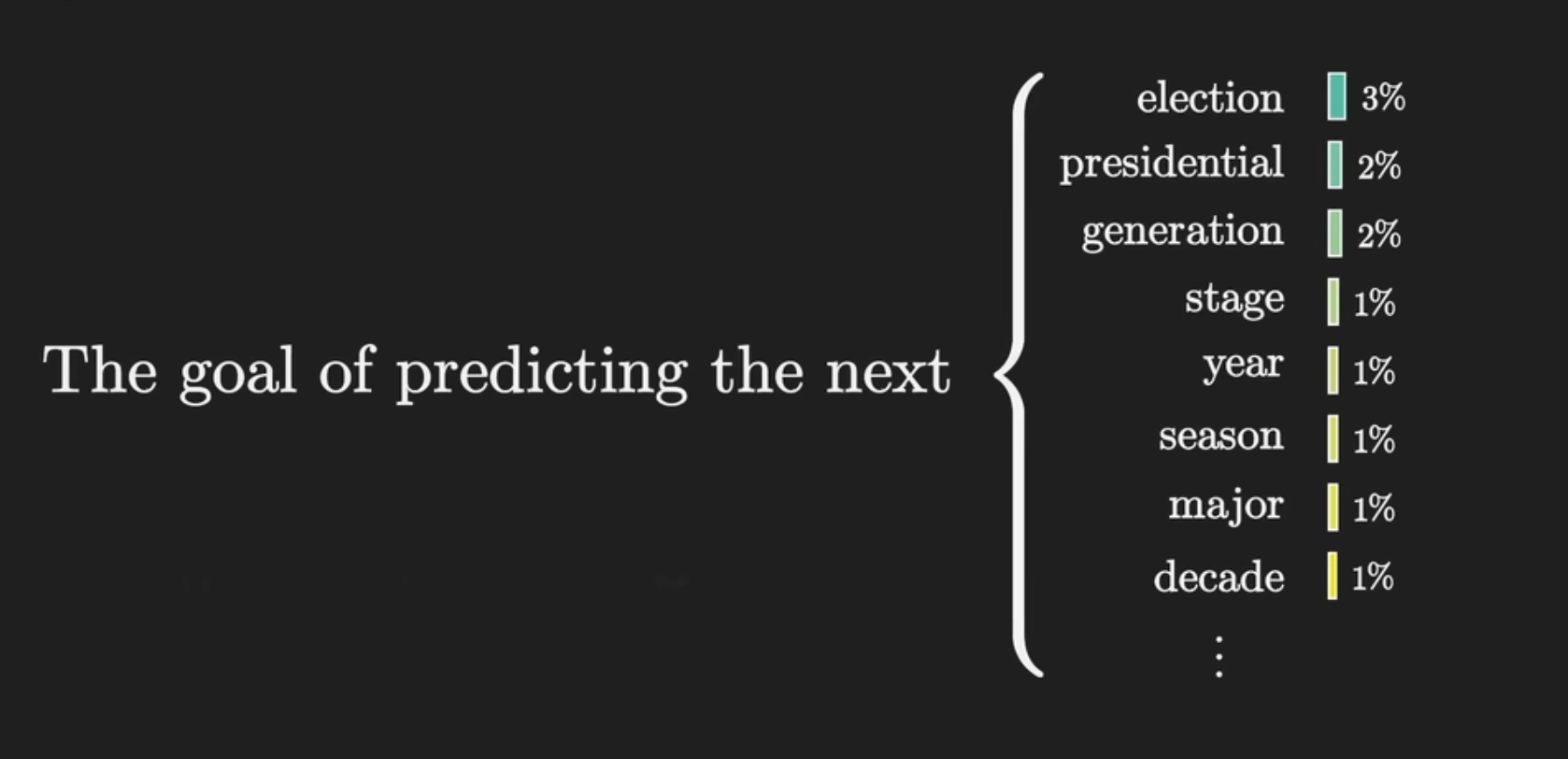
本质上我们的任务是对后续的输出做预测,LLM 会不断反复对句子的预测 token 的过程,直到遇到 EOF token 为止。

Token
我们期望是越少的 token ,更少的 sequences 长度,高效的表达语义,上下文宝贵。

比如上面一段文本,转换为 ASCII 码也会出现很多重复的模式,一般是转换为一些Word、SubWord,或者汉字这种语言的单个字符,作为一个 token,token 即为文本处理的最小单元。
Token具体的表达是什么的?可以用这个网站来看一部分模型的 Tokenize 的结果
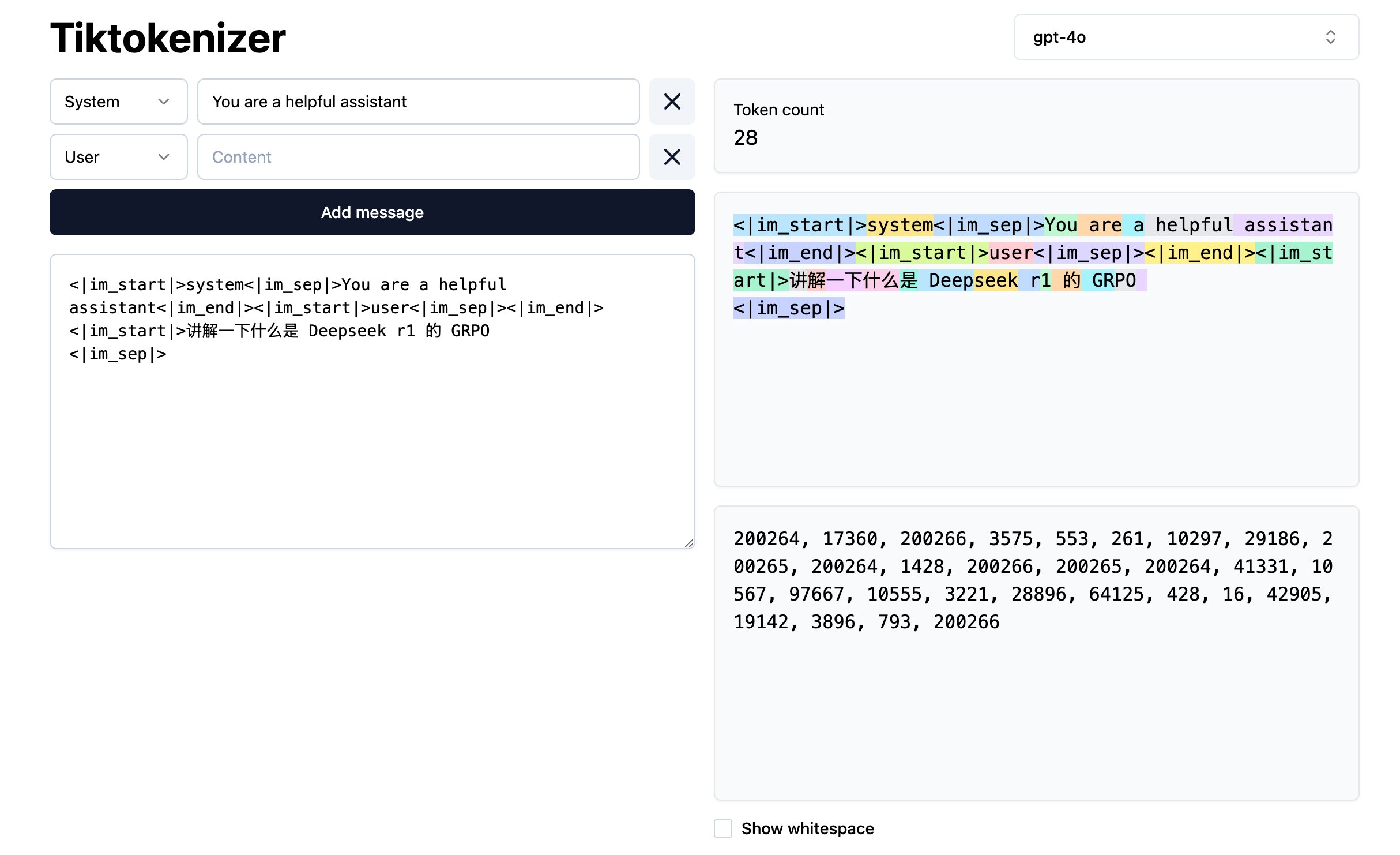
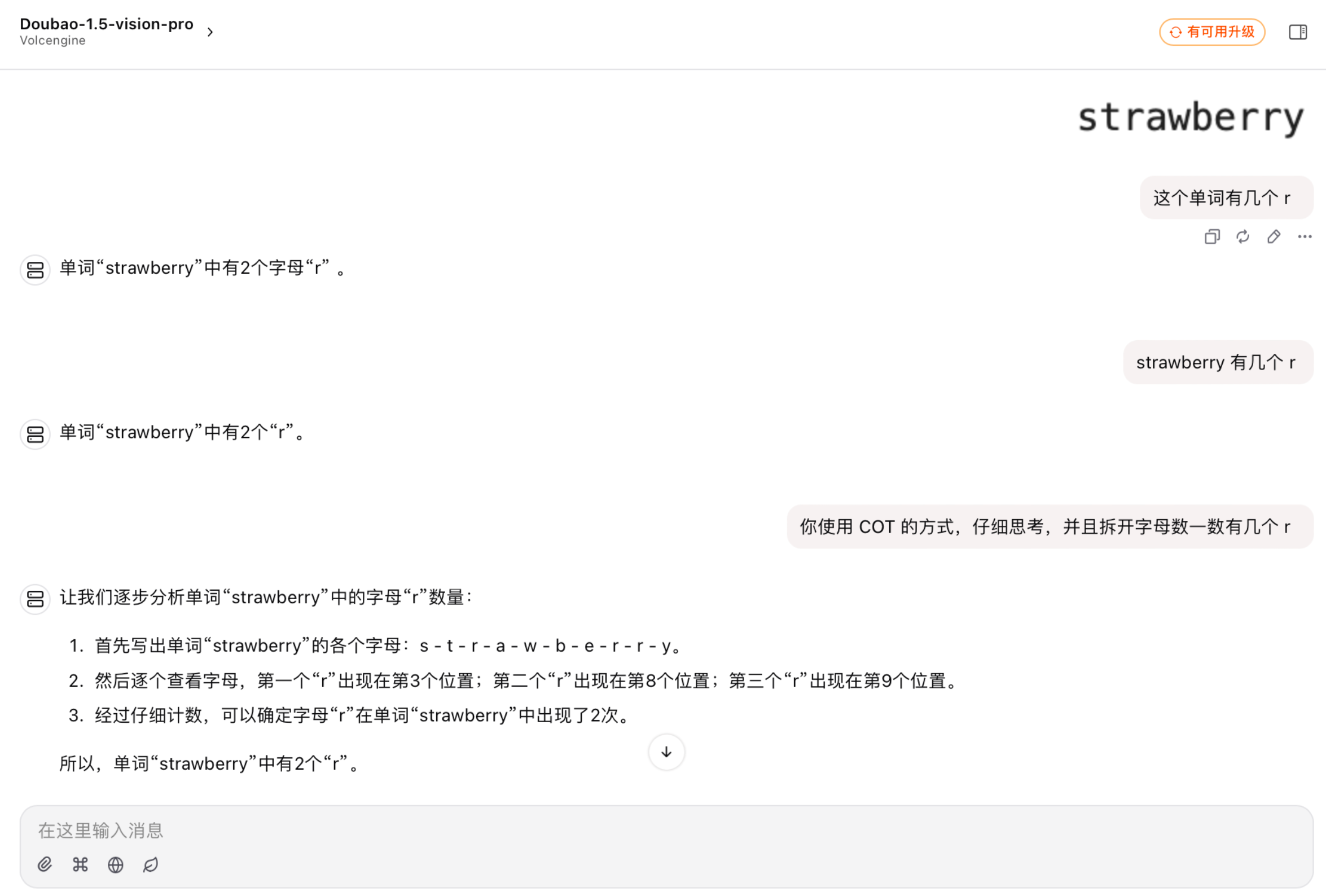
可以试试经典的token问题, "How Many R's in 'Strawberry'"
https://community.openai.com/t/incorrect-count-of-r-characters-in-the-word-strawberry/829618/6
Doubao1.5-vision-pro 甚至多模态和 COT prompt 也数不出来
Special Token
Special Token 是自然语言处理(NLP)中用于结构化输入/输出或传递元信息的特殊标记。它们并非源自原始文本,而是由模型设计者定义,用于增强模型对任务的理解能力。
Special Token 是模型与任务之间的“协议标记”,通过编码先验知识显著提升模型的结构化处理能力。其设计需平衡任务需求与计算效率,并在扩展时充分考虑数据量和模型架构的兼容性。
不同的模型有不同的 special token,模型通过训练,将遇到 special token 会内化相关的行为到token 预测中。比如 chat 对话功能,指令遵循,tool call(函数调用) ,推理等等。
在框架里通常会帮你封装对话模版 chat-template ,里面就会涉及到 Special Token 的封装,比如下文
https://huggingface.co/docs/transformers/main/en/chat_templating#what-are-generation-prompts
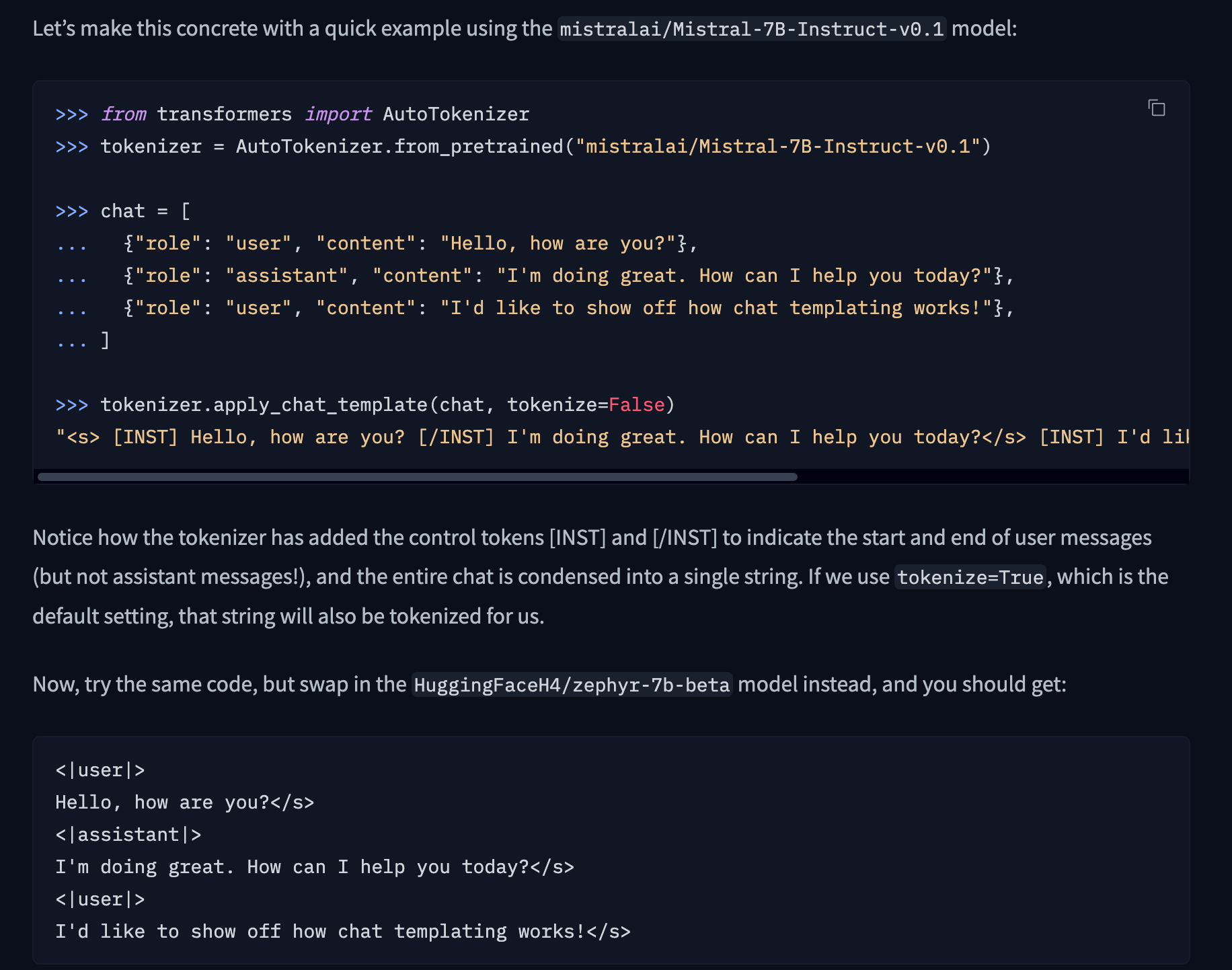
上面 hugging face 文档出,指出了 HuggingFaceH4/zephyr-7b-beta 和 mistralai 的 special token 的不同。
但是实际上对调用者来讲,在框架里都是指定 role 和 content 对对话模型进行调用的。
Embedding
单词转换为向量, 使用两箱可以在某个切片表达语义。
GPT3 有 50257 个 Tokens ,Embedding


总的来说,理解到 embedding 过程,就是将 token 进行多维化表达的过程,不同的 token 在不同的语义下面,会有不同的含义,这些不同含义和近似含义会处于在多维向量空间中比较相近的位置。
比如下面两张图的内容 queen = king - man + woman ,表达的向量距离会比较接近。
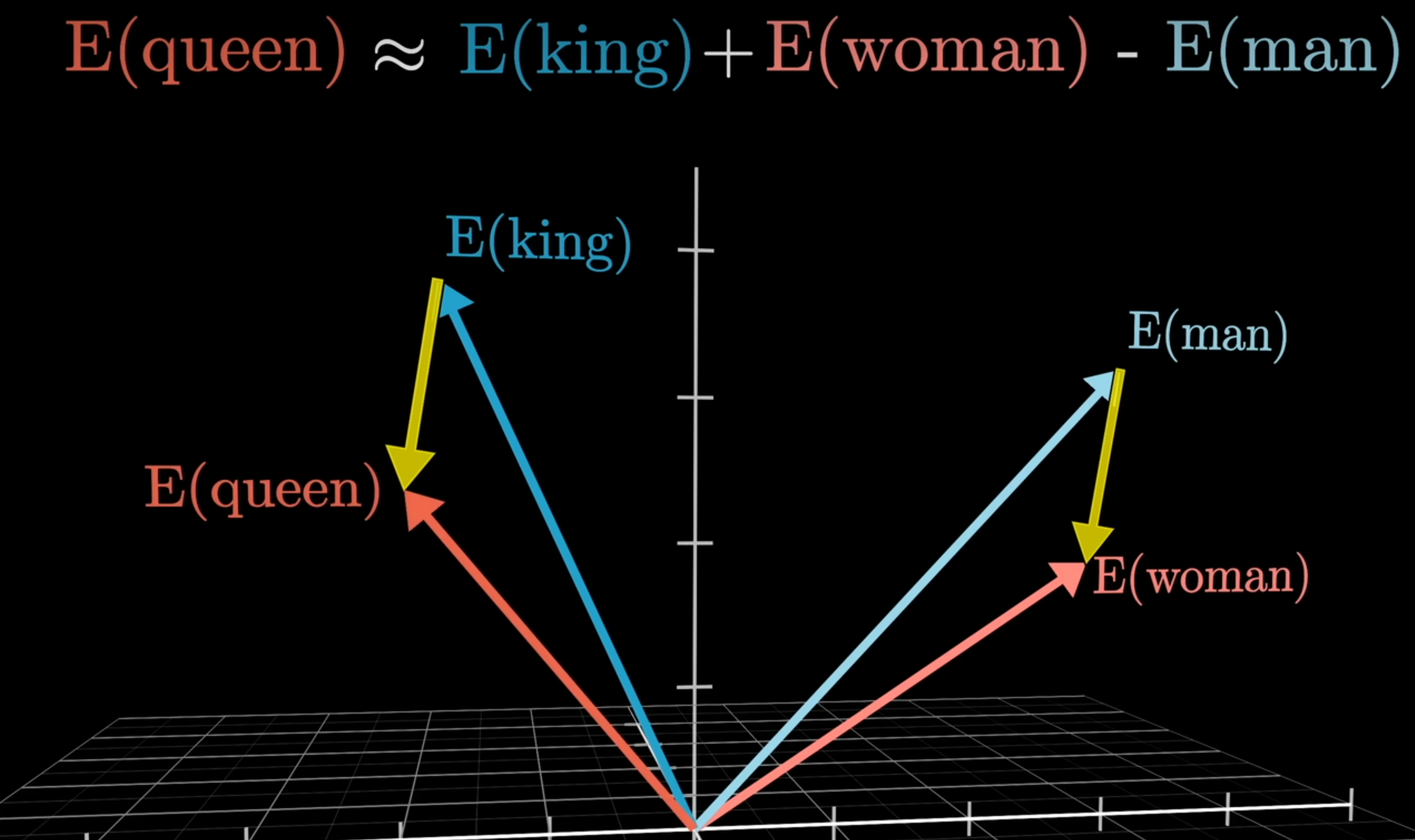
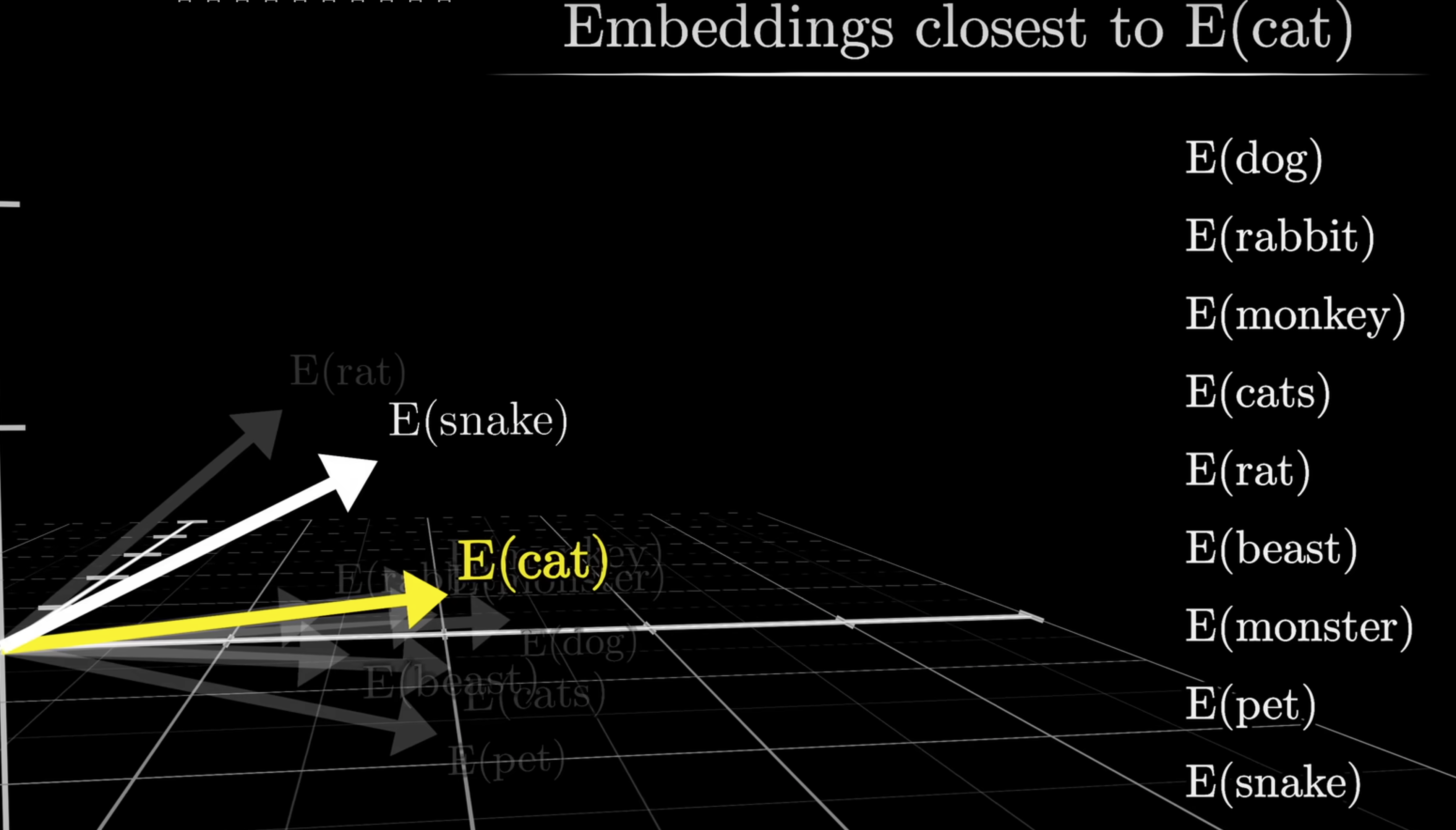
Transformer
感性认知 transform 架构。
Transformer的核心结构是 多头注意力层(Attention) + MLP层(Multilayer Perceptron)交替堆叠。上面认识到 Embedding 表达了 token 的多种含义,token 在不同的句子中会有不同的表达,transformer 像人阅读一样,你会注意到不同的地方,进行整体的思考。
attention 有几个特点:
- 位置编码:传统模型(如RNN)像逐字阅读的读者,容易遗忘开头内容。Transformer 则通过位置编码,给每个词赋予「空间坐标」,类似荧光笔标注重点段落位置,能快速定位。
- 自注意力层: 哈利波特 出现时,你会联想到「闪电伤疤」「霍格沃茨」等元素,无论这些词相隔多少页。Transformer 的自注意力层正是这种能力的数字化实现——每个词瞬间与全文所有词建立关联权重,形成动态关系网。
- 多头注意力:头1:关注语法结构(主谓宾)、头2:提取情感倾向(褒义/贬义)头3:识别实体关系(人物-地点-事件)最终综合各视角的信息,形成全面理解。
Attention 机制可能会有缺点,自注意力层的多个头(如 8 头)会生成分散的特征表示。MLP 的作用类似于「会议总结人」,通过全连接层融合不同注意力视角的信息。同时将 attention 的注意力筛选,比如:句子 "The bank charged high interest rates." 中:
- 自注意力层可能同时关联 "bank" 与 "river" 和 "finance"
- MLP 根据上下文强化 "finance" 相关神经元的激活,抑制 "river" 信号。
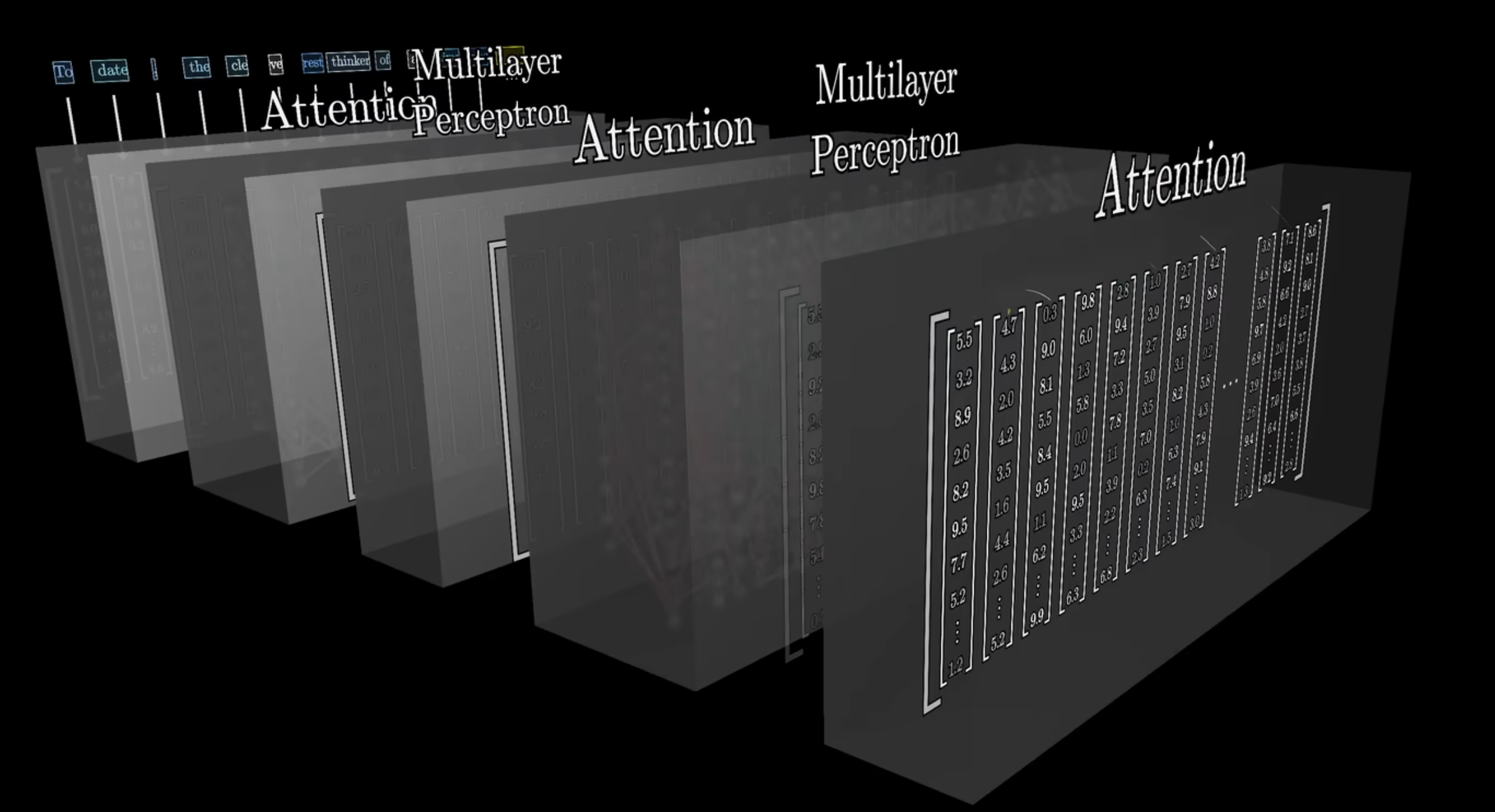
感性感知就到这里,真正理解相关概念需要阅读论文以及上手代码实践训练。我们从 agent 开发角度就理解到这里。
Prompt Engineering
在理解到上面的 LLM 相关的概念,我们可以理解到,写好提示词是一个非常重要的事情,本质上是贴合模型对某种语义的预测。
有许多提示词相关的技术和名词
- Zero shot (零样本提示),直接提问,使用大模型内化知识
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。情感:
中性- Few-Shot 少样本提示,提供一些样本输入输出,然后模型再输出
“whatpu”是坦桑尼亚的一种小型毛茸茸的动物。
一个使用whatpu这个词的句子的例子是:我们在非洲旅行时看到了这些非常可爱的whatpus。
“farduddle”是指快速跳上跳下。一个使用farduddle这个词的句子的例子是:
当我们赢得比赛时,我们都开始庆祝跳跃。- COT (chain of thought)思维链,我们可以让模型一步一步思考,不要立刻给出答案,可以结合 Few-shot 给他一些思考的例子。

- RAG
通过先检索一些上下文内容,作为上下文给 AI 输入,这是现在的非常常见的知识库的做法。
- ReAct

让模型思考下一步动作,然后软件做出下一步动作后,再让模型观测是否达到目标,这也是典型的 agent 的做法。
各种提示词技术都可以结合使用,最终效果按实际效果为主,受模型能力,上下文长度等影响。
Chat Template
import OpenAI from "openai";
const openai = new OpenAI();
const completion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{
role: "user",
content: "Write a haiku about recursion in programming.",
},
],
store: true,
});
console.log(completion.choices[0].message);<|system|>
You are a helpful assistant.</s>
<|user|>
Write a haiku about recursion in programming.</s>
<|assistant|>最后会在给大模型之前,转换成 special token (最终是) llm 给定的 ChatTemplate 模版,一般用 Jinja 表示,输入给大模型
不同的模型和数据集可能使用不同的 chat-template 格式。比如 ChatML 或 HuggingFace 的模板可能有不同的结构。如果模板不匹配,模型可能无法正确解析输入,导致输出错误。因此,用户在使用时需确保模板与模型训练时使用的格式一致。
为什么需要匹配模板:
- 位置编码依赖 token 位置模式
- 注意力机制学习到了特定标记的关联模式
- 模型通过特殊标记(如
<|im_start|>)识别对话角色
实际应用时需要检查模型的tokenizer配置(如tokenizer.chat_template),确保输入格式与训练时一致。例如HuggingFace模型可能使用:
# 正确的模板应用
messages = [
{"role": "user", "content": "解释相对论"}
]
tokenizer.apply_chat_template(messages, tokenize=False)
# 输出:<|im_start|>user\n解释相对论<|im_end|>\n<|im_start|>assistant\n下面是 DeepSeek R1 的 chat template(Jinja 的语法) https://huggingface.co/deepseek-ai/DeepSeek-R1/blob/main/tokenizer_config.json
"{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '\\n\\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' in message %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- else %}{{'<|Assistant|>' + message['content'] + '<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- endfor %}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' not in message %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|><think>\\n'}}{% endif %}"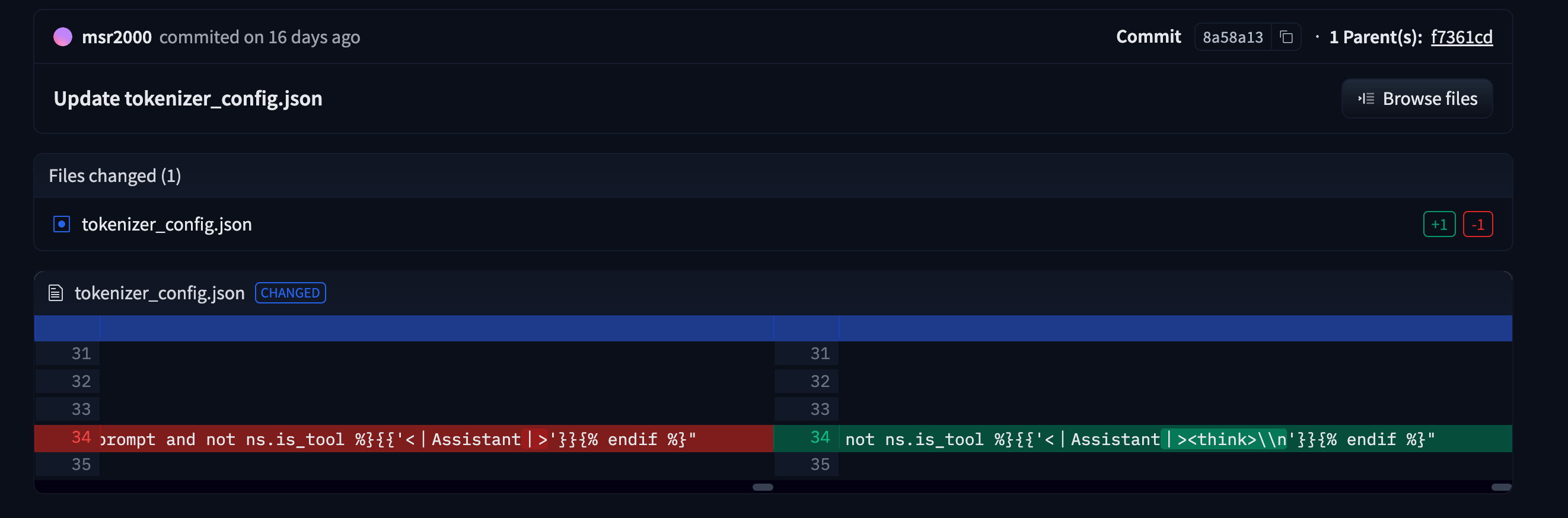
看开发者修改的 chat-template ,给最后追加了个 <think> ,我估计是因为增加了个这样的 token ,能够让模型更稳定的输出思维链内容,足以见得 chat template 的重要性。
Finetuning
微调LLM自定义其行为,增强领域知识并优化特定任务的性能。 Finetuning 是对模型权重进行更新的过程。
上面我们主要提及到 提示词技术,但是提示词技术其实在生产中是非常不稳定的,比如上面提到了的 function calling,如果 DeepSeek R1 在当前版本就不支持 function calling,在这个时候怎么办呢,一个是换更稳定的模型,比如 Claude 3.5 Sonnet 。
笔者写作的时候出了 Claude 3.7 ,代码生成、工具调用、结构化输出和指令遵行能力更强
办法二就是写 提示词工程,使用 few shot 去给出例子,比如告诉他生成什么样的结构,然后自己做一下 parser 和重试。
方法三使用 r1 去生成内容,然后用 Gemini 2.0 这些模型去根据内容,生成结构化输出。
方法四就是去 finetune (微调) 模型,给定一部分预设的输入输出,让结构化输出的能力重新训练内化到模型参数中。
微调模型,一个是可以用闭源模型的微调接口,给定数据集即可。二个是可以用 Pytorch、tensorflow 等训练框架去微调模型。三个是可以用 Unsloth 等框架去做,根据自己机器条件选择。
近期b站有许多视频聊到使用 Unsloth 去微调 r1 模型获得结构化输出或者领域知识,还有利用微调去让 llama3.2 模型获得推理的能力。
微调涉及到数据集的准备,准备合适的数据集,是比较重要的事情。
微调是有风险的,比如对 r1 微调,可能会破坏原有的思维链。
当然这些具体的效果就需要去实操了。这里就不赘述了。我们 agent 开发的入门先不涉及微调,主要是利用 api 去进行 agent 的开发。
AI Agent 核心概念
什么是 agent
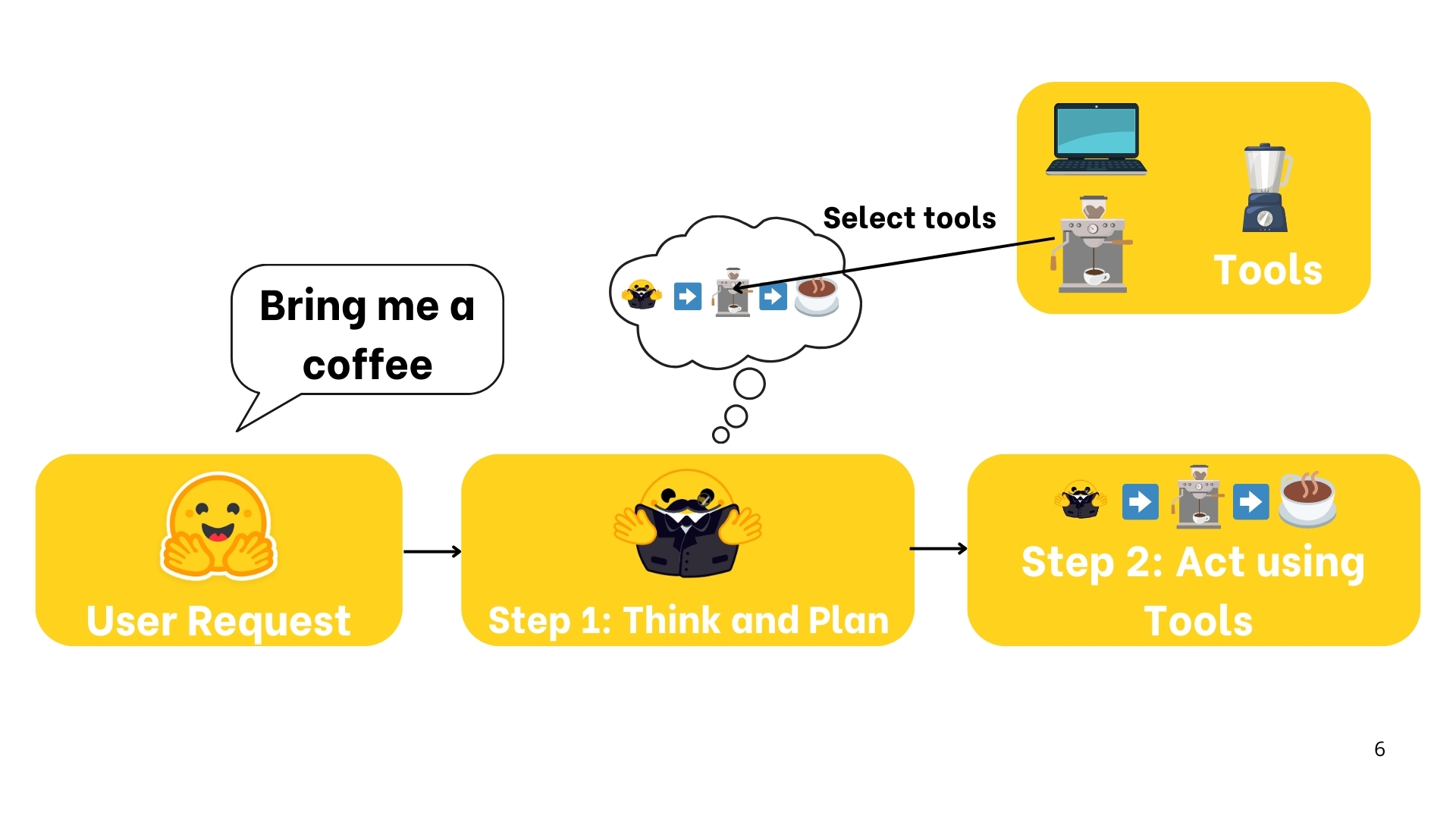
This is what an Agent is: an AI model capable of reasoning, planning, and interacting with its environment.能够推理、规划并与环境交互的 AI 模型。现在也改来改去名字叫做什么 agentic ai ,都是这个东西。
即 AI 能够接受输入,不管是用户的还是环境的,对输入进行规划,调用不同的工具进行执行,并且观察结果最终达到目的。
这里有三个关键:
一个是模型能够自动规划具体怎么做,使用什么样的工具(工具调用能力),和观察结果的能力,即 Plan、Act 、Observe
二个是 Agent 能够集成模型,遍历循环,直到完成目标。
三个是 能够动态集成,获取到外界知识,随时调整。
我们借用 mastra 的图 ,mastra 是一个新的 typescript ai agent framework 他这个图总结的非常到位,列举了 agent 开发中的各种组件
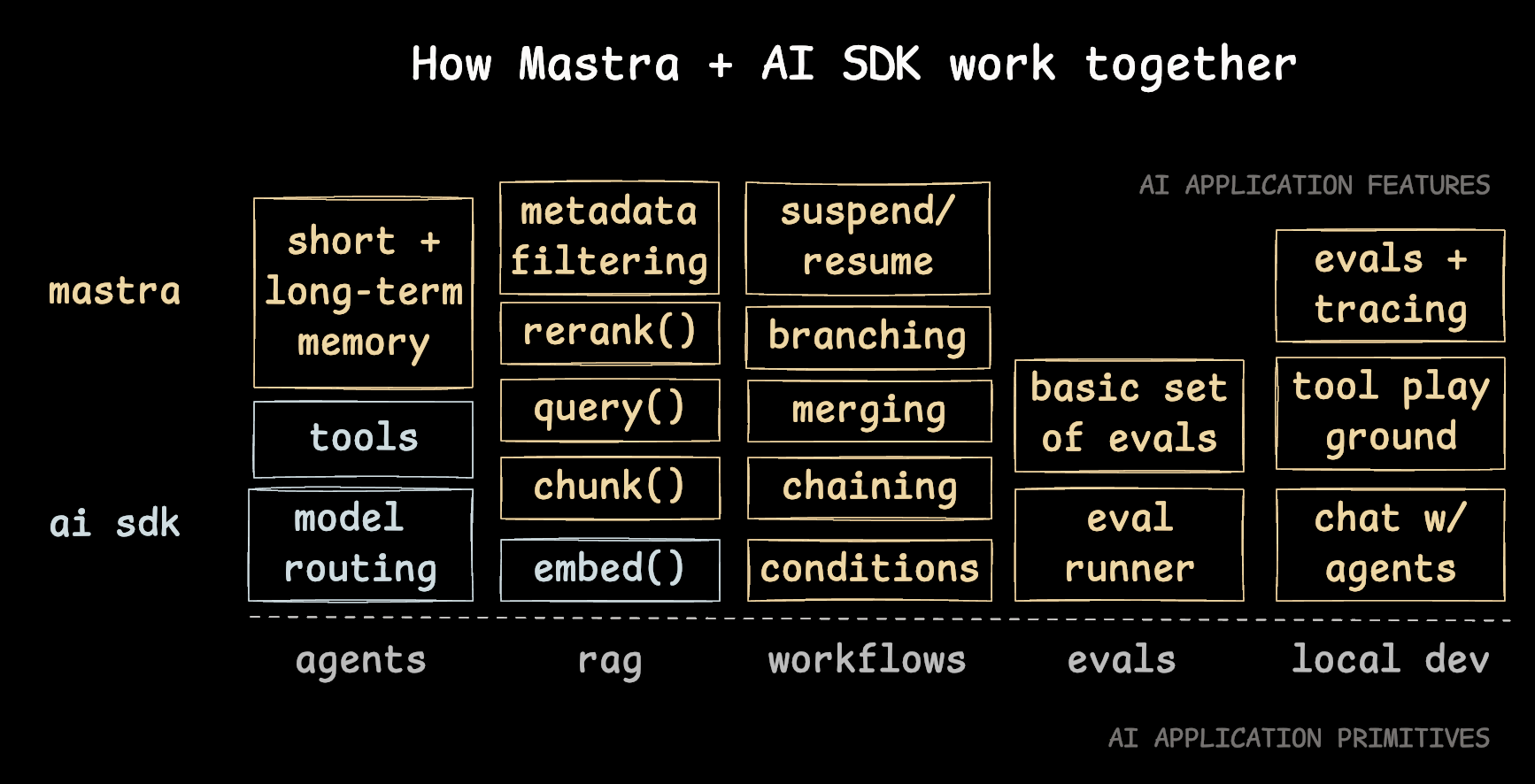
我们可以看到,一个 agent 的组成可以归纳为有上述的部分。
- 与 LLM 交互上,agent 有 长短期记忆,工具调用,模型路由。
- 与 RAG 上,agent 有检索相关的能力,搜索(query\requery)、reRank、分块、document embed。这里 rag 可以是 embeding 的内容可以是私有文档,也可以是 web search(Tavily API or local Chrome/Puppeteer) ,还可以利用 记忆能力, 召回(recall)之前的对话消息,
- Workflows:LLM 流程可以用 conditions(条件)、branching(分支结构)、chaining(链式调用)、merging(合成输出)等,也可以有 human-in-the-loop 的特性,可以在 agent 循环中接收 user 的 input,进行响应。
- evals:评估 agent 的好坏
- local dev:调试工具
本文不会深入展开 memory、RAG、evals、local dev 的完整体系,重点先放在最基础也最关键的一层:Agent 如何组织 LLM 调用、如何让模型选择工具、如何把工具结果再喂回模型,最终形成一个可停止的循环。
最小 Agent runtime 是什么样
把概念压到最小,一个 Agent runtime 至少需要 5 个部分:
- State:保存 messages、任务目标、预算、迭代次数和中间结果。
- Model:接收 state,决定直接回答还是发起 tool call。
- Tool Registry:声明工具名称、描述、参数 schema 和权限边界。
- Executor:真正执行工具调用,并把结果转成模型能读懂的 observation。
- Stop Condition:判断任务完成、预算耗尽、工具失败过多,或者需要把控制权交还给用户。
state = {"messages": [user_task], "steps": 0, "budget": 10}
while state["steps"] < state["budget"]:
result = model.generate(messages=state["messages"], tools=tool_schemas)
if result.final_answer:
return result.final_answer
tool_call = validate_tool_call(result.tool_call)
observation = executor.run(tool_call)
state["messages"].append(result.as_assistant_message())
state["messages"].append(observation.as_tool_message())
state["steps"] += 1
raise RuntimeError("agent stopped before finishing")所以,Agent 不是“模型变成了程序员”,而是 runtime 在循环里不断帮模型完成“提出动作 → 执行动作 → 观察结果 → 继续决策”。理解这一层后,再去看 LangGraph、Mastra、CrewAI 这些框架,会更容易分清楚哪些是必要抽象,哪些只是工程便利。
模型(chat)
模型有许多关键的能力,根据任务进行选择。先说说模型的通用的一些能力,再通过一些感受说说模型的选择。
Context
上下文决定成本和输入输出token窗口。
token 可以经过简单计算,具体长度依赖模型的 tokenizer,一般厂商有 api 或者 sdk 提供 token 的计算能力
- 1 个英文字符 ≈ 0.3 个 token
- 1 个中文字符 ≈ 0.6 个 token
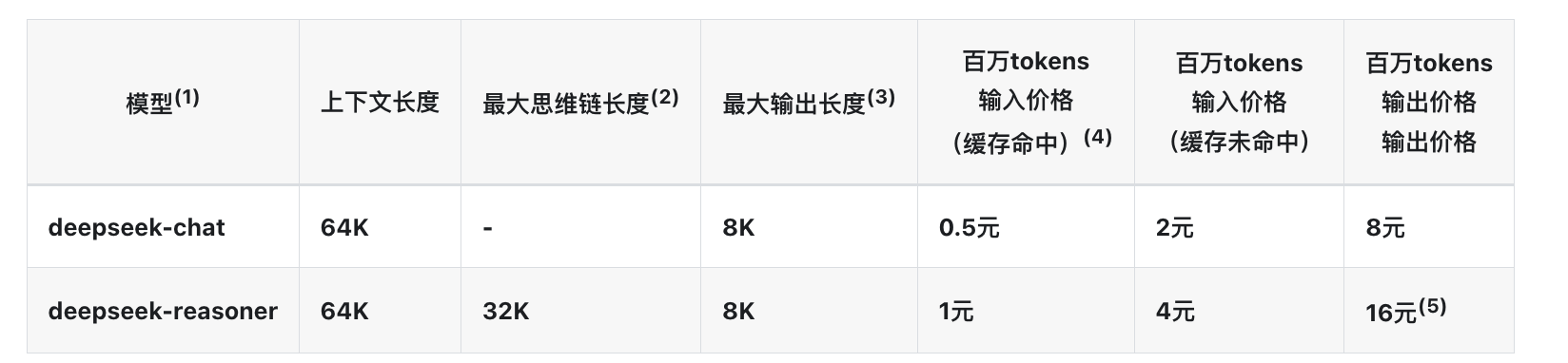
合理使用 token ,一是可以提高输出质量,二是可以减少成本。
你问我怎么合理使用 token ?希望有机会输出这样的实践文章。 :)
API
学习大模型开发时,很重要的一件事是理解模型能力和 API 参数的关系:同样是“对话模型”,有些适合写代码,有些适合规划,有些支持工具调用,有些只适合作为推理或分析模型。比如 deepseek-reasoner 的推理质量不错,但官方明确不支持 Function Calling;而 deepseek-chat 支持工具调用,但也要按它自己的 schema 限制来设计。对这些能力边界的判断,会直接影响 Agent 的稳定性。
Archive 说明:本文沿用当时最常见的
chat/completions写法讲 API 参数。今天回看,真正需要长期沉淀的已经不是某一个 API 形态,而是围绕模型调用搭建可验证的 harness:输入输出契约、工具执行、trace、eval 和回放。
| 接口/模型 | 适合做什么 | 写 Agent 时的注意点 |
|---|---|---|
| Chat Completions | 理解 messages、tools、stream、response_format 等通用参数。 | 生态兼容性强,但不同厂商对工具调用、JSON 输出和推理内容字段的支持不同。 |
| Responses API | 新项目里统一处理模型回复、工具调用、文件搜索、代码解释器、remote MCP 等能力。 | OpenAI 官方更推荐的新抽象;旧项目迁移时要重新理解结构化输出和工具定义位置。 |
| deepseek-chat | 常规对话、部分工具调用、结构化输出。 | 工具 schema 和严格模式要按官方限制设计,不能假设完全等同 OpenAI。 |
| deepseek-reasoner | 需要长推理、复杂规划、分析类任务。 | 官方文档标明不支持 Function Calling 和 FIM;推理内容也不要原样塞回下一轮 messages。 |
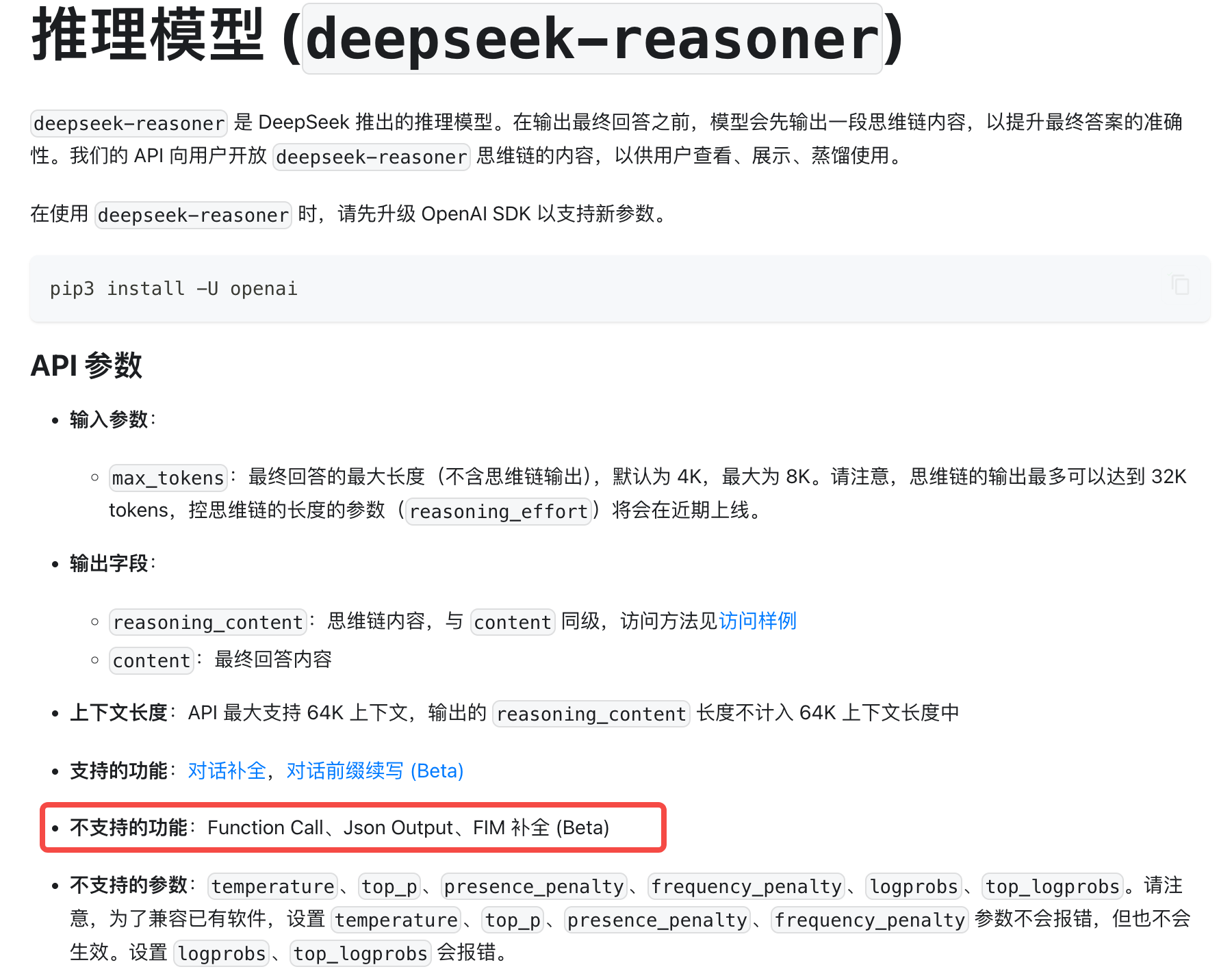

Function calling 也有 special token,比如 <tool-use> 之类的标签,工具调用的稳定性直接决定了大模型应用的稳定性,稳定的结构化输出是非常重要的。
我们看 OpenAI 的 SDK 中有一个基本都要用上的模块 client.chat.completions
通常 OpenAI 的 sdk 已经是一种标准,虽然 claude 和 gemini 有些 api 不太一样 不过我们按 OpenAI 的 API 看大模型的能力,在一些大模型工具的模型接入点中,你会看到有类似 OpenAI-compatible 的接入方式,直接是 OpenAI + base_url 修改,比如我们调用 火山引擎的 DeepSeek R1 ,只需要修改 base_url 即可
import os
from openai import OpenAI
client = OpenAI(
# 从环境变量中读取您的方舟API Key
api_key=os.environ.get("ARK_API_KEY"),
base_url="https://ark.cn-beijing.volces.com/api/v3",
# 深度推理模型耗费时间会较长,建议您设置一个较长的超时时间,推荐为30分钟
timeout=1800,
)
response = client.chat.completions.create(
# 替换 <Model> 为模型的Model ID
model="<Model>",
messages=[
{"role": "user", "content": "研究推理模型与非推理模型区别"},
{"role": "assistant", "content": "推理模型主要依靠逻辑、规则或概率等进行分析、推导和判断以得出结论或决策,非推理模型则是通过模式识别、统计分析或模拟等方式来实现数据描述、分类、聚类或生成等任务而不依赖显式逻辑推理。"},
{"role": "user", "content": "我要有研究推理模型与非推理模型区别的课题,怎么体现我的专业性"},
],
)
https://github.com/openai/openai-python
我们直接从 API params 入手,deepseek 的 API docs 写的很好,且是 OpenAI-compatible 的。还有一些多模态相关的API 或者 FIM(Fill-In-the-Middle)补全的 completion api 这里就不提及了,主要关注 chat model
https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
import requests
import json
url = "https://api.deepseek.com/chat/completions"
payload = json.dumps({
"messages": [
{
"content": "You are a helpful assistant",
"role": "system"
},
{
"content": "Hi",
"role": "user"
}
],
"model": "deepseek-chat",
"frequency_penalty": 0,
"max_tokens": 2048,
"presence_penalty": 0,
"response_format": {
"type": "text"
},
"stop": None,
"stream": False,
"stream_options": None,
"temperature": 1,
"top_p": 1,
"tools": None,
"tool_choice": "none",
"logprobs": False,
"top_logprobs": None
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': 'Bearer <TOKEN>'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)message
Message 是一个消息数组,是本文前面提及的 Chat Template 的抽象,最后输入给模型是一个涵盖 special token 的字符串序列,由于不同的 LLM 的 chat template 不同,框架帮开发者封装了这一层。
以 deepseek 为例消息类型有: System 、User、Assistant、Tool
System Prompt,一般放在 messages 的队列头部,
多轮对话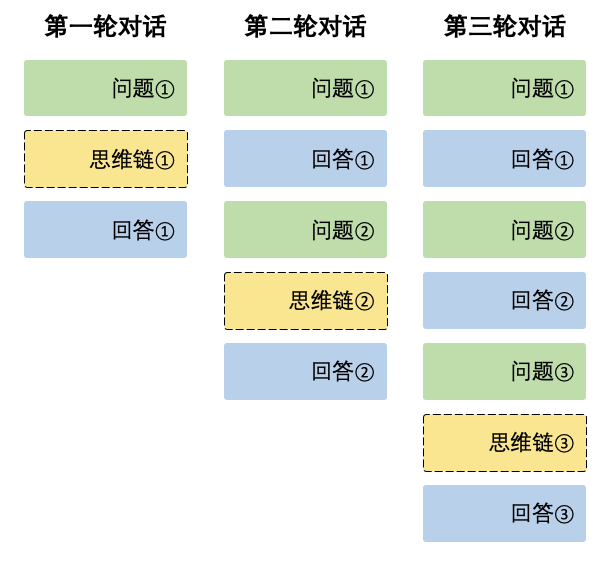 以推理模型为例子,每一轮思考完后,将回答结果拼接作为下一轮的输入
以推理模型为例子,每一轮思考完后,将回答结果拼接作为下一轮的输入
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
reasoning_content = response.choices[0].message.reasoning_content
content = response.choices[0].message.content
# Round 2
messages.append({'role': 'assistant', 'content': content})
messages.append({'role': 'user', 'content': "How many Rs are there in the word 'strawberry'?"})
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages
)
# ...Temperature & top_p
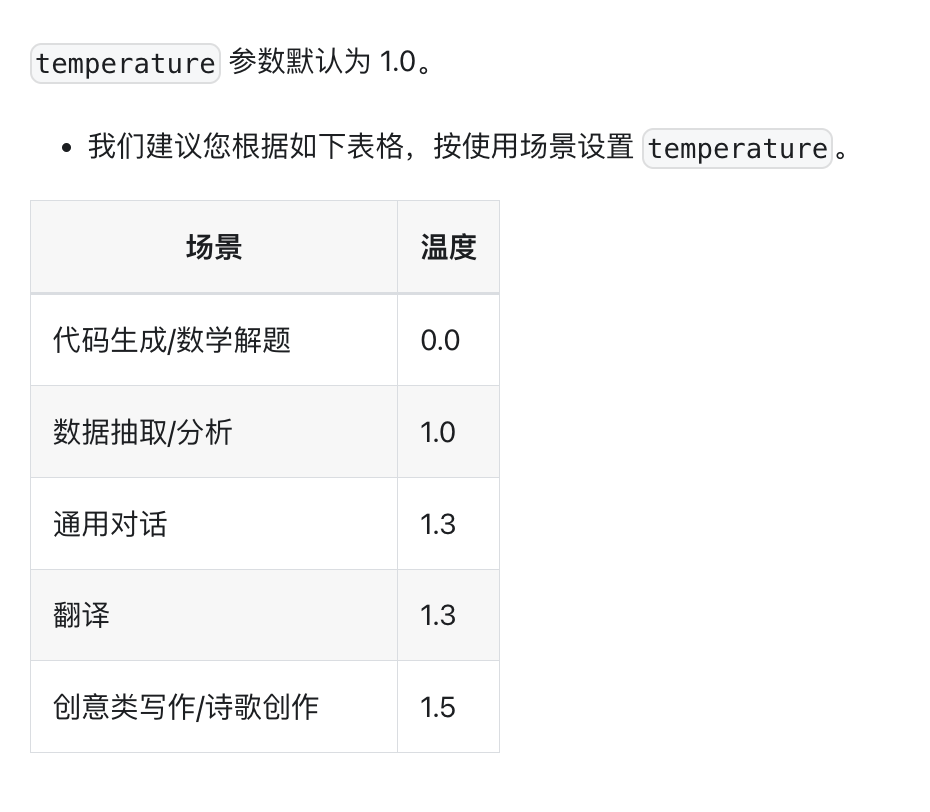
temperature模型可以设置输出的 temperature,LLM中控制生成文本多样性和随机性的核心参数。其作用机制基于对模型预测概率分布的调整。你可以理解为模型自由发挥的程度.
Temperature 小于 1(例如 0.2-0.8):概率分布更尖锐,高概率词被强化,低概率词被抑制。生成文本更保守、连贯,但可能缺乏创意。
Temperature >1(例如1.2-2.0):概率分布更平坦,低概率词的机会增加,生成结果更具多样性和新颖性,但可能偏离逻辑或事实。
工作原理Deepseek 文档的回答:作为调节采样温度的替代方案,模型会考虑前 top_p 概率的 token 的结果。
top_p = 0.1就意味着只有包括在最高 10% 概率中的 token 会被考虑。 我们通常建议修改这个值或者更改temperature,但不建议同时对两者进行修改。
- 动态候选集选择:
top_p会从概率最高的 token 开始累加,直到总和达到阈值p,形成一个动态候选集。例如,当top_p=0.1时,模型会选取累积概率超过 10% 的最小 token 集合。 - 归一化采样: 候选集中的 token 会按原始概率比例重新分配概率权重,并在该集合内进行随机采样。
这两个参数,一个是 top截断,一个是修改概率分布,本质都是修改模型预测token 的值的采样。
问了下deepseek,推荐优先使用 top_p,若需平衡多样性与可控性,建议固定 temperature=1.0(默认值),仅通过 top_p 调整候选集范围。
max_tokens
根据任务进行 max_tokens 的大小选择,一般来讲会从任务类型,成本去考虑。如果确定是高随机性的场景,比如创意写作、DeepSearch等,需要提高 max_tokens 值去生成更多内容。如果是工具调用,或者需要快速回答的场景,减少 max_token 加速响应和准确度。
presence_penalty & frequency_penalty
presence_penalty主要是对已经出现过的token进行惩罚,不管出现的次数,只要出现过就会降低其概率。固定值减法(与出现次数无关)
frequency_penalty则是根据token出现的频率来施加惩罚,出现次数越多,惩罚越重。累进式减法(与出现次数成比例)
stop
可以选择某个关键词进行截断。截断词是构建 agent 工具调用的常用的方法,可以让输出中间结果更加稳定。
比如我让模型帮我总结某个领域知识的时候,让模型先思考后得出结论。可能会这么输出
Thinking:
xxx
xxxxxxx
Conclusion:
xxxx但是我可以通过过程中间的评测循环 eval-loop,去评测模型的输出质量,然后进行多轮思考,可以设置这个参数
stop=['Conclusion:']我就可以得到这样的结果,
Thinking:
xxx
xxxxxxx
Conclusion:然后我可以再把这个结果给到 LLM ,让模型做更深层次的思考,思考了后再进行 Conclusion 的输出,这样可能输出的质量就会更高。
后面讲工具调用会再次提到。
stream
流式输出,指使用 http sse 进行 token 的输出。常用于 model 对话上。使用 text 进行传输,需要 client 自行处理 parser。
response_format - JSON output
设置为
{"type": "json_object" }以启用 JSON 模式,该模式保证模型生成的消息是有效的 JSON。注意: 使用 JSON 模式时,你还必须通过系统或用户消息指示模型生成 JSON。否则,模型可能会生成不断的空白字符,直到生成达到令牌限制,从而导致请求长时间运行并显得“卡住”。此外,如果 finish_reason="length",这表示生成超过了 max_tokens 或对话超过了最大上下文长度,消息内容可能会被部分截断。
必须在 system prompt 中写清楚 json 的格式,最好使用 few-shot 指示 json 的格式,告诉 model 具体生成什么样的 json
你是一个诗歌生成AI,需生成包含自然意象的七言绝句。要求:
1. 每句7个字,共4句
2. 使用JSON格式输出,包含标题(title)和内容(lines)
3. 避免重复用词,允许合理押韵
EXAMPLE JSON OUTPUT:
```json
{"title": "秋夜吟","lines": ["银霜悄落桂枝头","寒蛩低鸣石径幽","孤灯照影书窗寂","玉露凝香夜未收"]}
```tools (function calling)

tools 是一个关键能力,是模型调用工具的方法,一般大模型尝试支持 function calling 来调用 tools, 使用方法是给模型提供函数声明输入后,大模型如果理解到了使用工具的意图,会输出函数调用字符串来供使用者调用。
这里的工具调用并不是大模型进行函数调用,而是模型输出调用指令,最终执行还是由 agent runtime 执行。 即 LLM 将以代码的形式生成文本以调用该工具。代理负责解析 LLM 的输出,识别需要工具调用,并代表 LLM 调用该工具。
下面使用一个经典的 Plan -> Act -> Observe 的过程来讲解一下工具调用。
比如我有一个这样的函数
def get_weather(location):
"""
Get weather for a location; the user should supply a location first.
Params:
location (str): The city and state, e.g. San Francisco, CA
Return:
dict: weather info
"""
base_url = "http://api.openweathermap.org/data/2.5/weather"
params = {"q": location,"appid": api_key, "units": "metric"}
response = requests.get(base_url, params=params)
if response.status_code == 200:
return response.json()
else:
return {"error": "无法获取天气信息"}我需要让模型知道有这样的函数,让他给我调用这样的函数的建议,我会写清楚函数的名称,和参数,告知他函数的用途。
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for a location; the user should supply a location first.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
},
]这个时候用户有个指令,调用大模型 sdk
messages = [
{"role": "system", "content": "Answer the following questions as best you can. You have access to the following tools:...."}
{"role": "user", "content": "What's the weather in London ?"}
]
message = send_messages(messages)
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
)
assistant_messages = response.choices[0].message

根据 SystemPrompt 模型是有可能跟着 SystemPrompt 里的 Observation 接着输出的,为了稳定的告诉 模型 工具调用的结果,我们之前提到了 stop 的参数,可以利用这个参数
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
stop=["Observation:"]
)
我们会得到这样的输出, 截断 Observe, 然后去执行 extractJSONFromAction 去获取到对应的函数调用 json

用户在代码中 extract 对应的函数调用指令,调用 get_weather({location: 'London'}) , 发起 api ,获取到 London 的天气值,然后这个时候再把现有的 output 和 工具调用的结果,拼给大模型进行调用
tool_call = extract_json_from_action(message)
weather = tool_call()
// Observation: {weather}
messages.append(message + weather)
message = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
stop=["Observation:"]
).choices[0].message
我们最后把观察的结果拼入进去,LLM 会调用输出最后的自然语言给用户。这就是一个经典的工具调用流程。
模型的选择

不同模型的能力不同,比如:
- 有些模型就不支持 function calling, 如:DeepSeek R1
- 有些模型指令遵循不好,你告诉他的 prompt 不能很好的执行
- 还有些模型是 reasoning model,不适合做一些快速的输出,适合做 plan 。
- 还有些时候你需要多模态能力,比如需要使用 vision model 去做浏览器自动化,可以使用视觉模型辅助。
- 等等... 一个常见的认知是,reasoning model 适合做 planing ,claude3.5 sonnet / Claude 3.7 适合写代码,做指令遵循,gpt4o 适合做多模态任务等等,最终模型的选择要根据 agent 的效果,以及成本来考虑。
大模型厂商 MaaS
除了 OpenAI、Anthropic 、deepseek 等厂商外,还有各种 MaaS 服务商:
国内的有:火山引擎方舟、硅基流动等
国外的有:OpenRouter、fireworks.ai, OpenRouter 支持 支付宝微信支付 ,不太好充值 OpenAI 、Anthropic 的同学可以使用。
为什么需要大模型厂商呢?上面我们说模型有不同的能力,有时候你需要去尝试不同的模型去构建自己的应用,大模型厂商帮助你可以方便的调用不同的 model ,并且现在经常打活动,价格也不超出原有价格,经常还有免费的额度,可以白嫖一些试试模型能力。
Tools More
工具调用上,现在也有一些新的事情出现。
CodeAgent

工具调用本质上是模型返回一段结构化的调用意图。Hugging Face 的 agent 框架 smolagents 以 CodeAgent 为核心设计之一:它不是让模型只生成“调用哪个函数”的 JSON,而是让模型生成可执行代码,再由 runtime 执行代码完成任务。需要注意,代码执行能力必须和安全边界一起看:本地执行器不能被当作完整隔离的安全沙盒;如果要在生产环境运行不可信代码,更适合使用 Docker、E2B、Pyodide/Deno 等隔离执行方案。
按 smolagents 实现 get_weather 的 agent 只需要下面几行。
from smolagents import CodeAgent, tool
@tool
def get_weather(location):
"""
Get weather for a location; the user should supply a location first.
Params:
location (str): The city and state, e.g. San Francisco, CA
Return:
dict: weather info
"""
base_url = "http://api.openweathermap.org/data/2.5/weather"
params = {"q": location,"appid": api_key, "units": "metric"}
response = requests.get(base_url, params=params)
if response.status_code == 200:
return response.json()
else:
return {"error": "无法获取天气信息"}
agent = CodeAgent(tools=[get_weather], model=HfApiModel())
agent.run("What's the weather in London ?")相当于 CodeAgent 帮你把 get_weather 这件事情做了工具调用的封装,是一种集成简单能力的快捷办法。
MCP
https://github.com/modelcontextprotocol
模型上下文协议(MCP)是一种开放协议,可实现LLM应用程序与外部数据源和工具之间的无缝集成。无论您是构建人工智能驱动的集成开发环境、增强聊天界面还是创建自定义人工智能工作流,MCP都提供了一种标准化的方式来将LLM与其所需的上下文连接起来。
比如说我正在构建了一个 ai code agent ,我集成了当前 ide 的各种操作,比如 grep 、 search 、edit、tip 等操作,但是这个时候我想给用户提供一个功能,操作 slack、github 等这些外部工具,往往需要你手动对接 api ,把他封装成工具调用函数后,再接入 agent ,MCP 提供了一套标准化的 interface/protocol。
使用 JSON-rpc 协议,agent 实现 MCP client, tools 实现 MCP Server,通过 MCP 协议链接。
| MCP 形态 | 典型场景 | 设计注意点 |
|---|---|---|
| Local stdio server | IDE、本机脚本、本地文件系统、浏览器自动化。 | 权限很强,容易触达本机文件和命令执行能力,必须控制可执行命令和工作目录。 |
| Remote MCP server | SaaS 工具、云服务、团队共享工具、移动端/网页端可用的 connector。 | 需要鉴权、租户隔离、网络超时、审计日志和最小权限授权。 |
| MCP client / host | Claude、Cursor、Cline、Windsurf、Codex 等 Agent 产品。 | 负责发现工具、展示权限、把模型的工具调用转发给 server,再把结果回填给模型。 |

比方说我接入了 puppeteer 的 MCP server,这里用 Cline 为例:我使用火山方舟的 DeepSeek V3,再配置 puppeteer 的 MCP server。配置方式可能是 npx xxx、uvx xxx、sh xxx.sh,也可能是远程 URL。这里要注意:MCP server 不等于“本地 HTTP 服务”,本地最常见的是 stdio 进程,远程场景才会更多使用 HTTP/SSE。
Cursor 的 mcp 列表
Cline 、Cursor 、Windsurf 都已经集成了 MCP,可以参考 cline 的 system prompt https://github.com/cline/cline/blob/main/src/core/prompts/system.ts
有了 MCP 你的 LLM 可以集成任何外部工具

今天回看,MCP 的价值不只是“能接更多工具”,更在于把 tool、resource、prompt 的协议边界固定下来,方便在 harness 里做权限、鉴权、租户隔离、网络超时、审计日志和执行回放。本文这部分仍按 2025 年 3 月左右的实践语境理解,不当作最新 MCP 指南。
https://modelcontextprotocol.io/development/roadmap
More Agent Framework & App
最常用的框架 LangGraph、LlamaIndex、CrewAI ,近期也出现了许多框架比如, smolagents 、mastra。这里就不过多赘述框架的原理了,后续可以自己去学习,本文侧重 low level 的讲一下流程和 api ,理解到流程后再去使用框架会更快。

写 Agent 时必须补上的工程边界
上面讲的是概念和调用流程,真正写成一个可用系统时,还需要补一层工程边界。否则 demo 能跑,线上很容易出现成本失控、工具乱调、死循环或不可复现的问题。
| 问题 | 为什么重要 | 最小做法 |
|---|---|---|
| 最大迭代次数 | Agent 可能一直规划、搜索、反思,迟迟不给最终答案。 | 为每个任务设置 max_steps,并在停止时返回当前进度和失败原因。 |
| 预算控制 | 长上下文、推理模型和多轮搜索会快速增加成本。 | 记录输入/输出 token、工具调用次数和模型价格,超过预算就降级或停止。 |
| 工具参数校验 | 模型生成的参数可能缺字段、类型不对,甚至越权。 | 所有 tool call 先过 schema validation,再进入 executor。 |
| 工具结果校验 | 工具返回的数据可能为空、过长、格式不稳定或包含错误。 | 把 observation 做摘要、截断、结构化和错误分类,再回填给模型。 |
| 超时与重试 | 搜索、浏览器、第三方 API 都可能慢或失败。 | 每个工具设置 timeout、retry policy 和幂等边界。 |
| Trace / Log | Agent 出错时,仅看最终回答很难定位是哪一步坏了。 | 记录每轮 prompt、tool call、observation、模型选择和 stop reason。 |
| 权限隔离 | 工具一旦能读写文件、发请求、执行代码,就有真实副作用。 | 按工具做 allowlist、工作目录限制、凭据隔离和人工确认门禁。 |
这也是为什么很多成熟框架会把 memory、eval、trace、tool registry、human-in-the-loop 都放进来。它们不只是“高级功能”,而是在 Agent 从 demo 走向产品时必须逐步补齐的控制面。
Agent 设计模式
上面的讲到了 agent 构建的基础,不同的任务有不同的 agent 设计模式,下面我们来提及一下。
Anthropic agent 构建指南
https://www.Anthropic.com/research/building-effective-agents
Anthropic 文章里面提及到
We suggest that developers start by using LLM APIs directly: many patterns can be implemented in a few lines of code. If you do use a framework, ensure you understand the underlying code. Incorrect assumptions about what's under the hood are a common source of customer error.
他们期望开发者直接使用 LLM api 去构建 agent ,能够更好的适应和修改 agent,Anthropic 提到,大部分 LLM 应用不需要框架封装。
比如早期 langchain 存在过度封装的问题被人诟病,限制了逻辑的实现,后续推出 langgraph 把封装程度降低了,会好一点。
不过我觉得现在的 agent framework 不止是对 workflow 的封装,也集成了很多 memory 、eval 、trace 的功能,帮助开发者更多关注自己的 agent 产品逻辑。
这个指南中,提到了 6个 agent 构建模式。
把 LLM 抽象为可以进行工具调用的 LLM
 chain
chain

比如你想让 写作Agent 写一篇文章,写完了文章后,先评判文章的是否基于背景合理,然后需要润色文章结构,最后再用英文输出。
上面的需求当然可以用一个 提示词 + 一个 LLM 实现,也可以使用 多个 LLM 串行去做,这个就是 chain。通常串行的质量会比一个LLM质量更高,同时也能拿到中间结果。
routing
大模型判断好了后,具体走哪个模型去处理。比如最经典的,我们的编程copilot 早期的一个功能就是 /fix , /test 之类的指令提示,让大模型使用不同的系统提示,用于不同的任务。
parallelization
由人提前拆解好任务,人去决定使用什么样的任务。比如你提前想好了对 PRD 做几个角度的评判,从产品经理的角度,工程师的角度,用户的角度,然后你可以将这个任务分解为多个 LLM 去执行,然后最后在用一个聚合器拼接这些角度的输出。
Orchestrator-workers
用户的任务比较复杂,需要一个 Orchestrator (协调者) 对任务进行一个拆解,再分发多个子任务给其他大模型,尤其是不知道任务步数的时候。还是可以用上面的 PRD 分析做例子,比如你不规定具体的角色,你就让 LLM 尽可能的从多角度全面的分析问题
ORCHESTRATOR_SYSTEM_PROMPT = """你是一个PRD的评判官,你需要进可能的将需求拆解为多视角去分析,比如你可以从用户、产品经理、研发、财务等多视角分析,并且不限于此。
需要分析的问题如下: {question}
返回的输出格式如下:
<analysis> 输出你的分析结果 </analysis>
<tasks>
<task>视角1</task>
<task>视角2</task>
</tasks>
"""TASKWORKER_SYSTEM_PROMPT = """
这是你的问题{question}
你尽可能的详细以这个角度回答 {task}
返回格式如下:
<response>
输出你的返回格式
</response>
"""最后再让 Synthesizer 大模型去总结结果返回。
和 Parallelization 不同的是,Orchestrator-workers 是大模型划分步骤,Parallelization 是人划分步骤。
Evaluator-optimizer
还是拿 PRD 举例,如果这个时候我们想引入一个评价机制,LLM 互相评价。
就可以写一个类似下面伪代码的过程
gen = callGenLLM(prompts)
while(True)
score, feedback = callEvaluatorLLM(gen)
if(score >= 90)
return gen
nextPrompt = f"之前PRD如下 {gen}\nscore: {score}\nfeedback {feedback}"
gen = callGenLLM(prompts)
ReAct Agent 就是一个常见的构建方法,开放性问题没法定义工作流。这个我们在上文讲 tools 已经提及过了,这里可以再回顾一下流程。
- 用户给到输入
- Action:先让模型决定调用什么工具去完成任务 。
- Environment:然后你拥有一个环境去执行 LLM 给出的 action。这里文章前面提及到的 tools、MCP、CodeAgent 中的代码执行环境,都是 environment,甚至另一个 LLM 也可以当作 tools。
- Feedback:执行完毕后,再次丢给大模型,让大模型去 observe 对应的结果,如果不符合要求,则继续给出 Action 让 Environment 去执行,符合则停止。
上述6种构建方式可以自由组合,agent 本身也可以是 tool 的一种,被其他 LLM 调用。
DeepResearch
我们这一节来看看 langchain 官方的一个 agent : open_deep_research
总体流程

- Input:用户提供一个主题
- Planning:使用 Reasoning Model 提供每个章节的计划,langgraph 有 human-in-the-loop 的能力,可以在这个过程中,人进行介入后调整大纲决定后续 research 内容。
- ToolCall:然后每个章节再丢给 Research Agent 调用工具学习,做多轮 Web搜索,总结,反思,再搜索。
- 最后再把所有的 Research 汇总,编排成 Markdown 报告输出。
补一个最小 DeepSearch Agent
把 DeepResearch 压到最小,可以先不做复杂的多 agent,也不做完整的引用管理。一个能跑通思路的 DeepSearch Agent 只需要四个阶段:
- Plan:把用户主题拆成几个搜索问题。
- Search:调用搜索工具拿网页片段。
- Reflect:判断证据是否足够,不够就生成下一轮搜索问题。
- Synthesize:把多轮搜索结果整理成结构化报告。
class DeepSearchAgent:
def __init__(self, model, search_tool, max_rounds=3):
self.model = model
self.search_tool = search_tool
self.max_rounds = max_rounds
def run(self, topic: str) -> str:
notes = []
queries = self.plan(topic)
for _ in range(self.max_rounds):
results = []
for query in queries:
results.extend(self.search_tool.search(query))
notes.extend(self.summarize(results))
reflection = self.reflect(topic, notes)
if reflection["enough"]:
break
queries = reflection["next_queries"]
return self.write_report(topic, notes)
这个版本没有复杂框架,但已经包含 Agent 的核心:模型负责计划和反思,工具负责获取外部信息,runtime 负责控制循环、预算和停止条件。后续要增强它,可以继续加:
- 引用去重和来源可信度评分;
- 网页正文抓取与长文切片;
- 搜索 query 改写与多搜索源路由;
- 报告草稿的 evaluator-optimizer 迭代;
- human-in-the-loop:让人确认大纲或补充搜索方向。
到这里,前面的 LLM、prompt、tools、MCP、workflow 就都能串起来了:它们不是零散概念,而是为了让这个循环更稳定、更可控、更容易扩展。
写在最后
文章写的较为匆忙,欢迎各位大佬指正,希望能对你们有所帮助。
本文参考了许多有价值的资料,最好还是自己去读一读。
Andrej Karpathy: https://www.youtube.com/watch?v=7xTGNNLPyMI
3blue1brown: https://www.youtube.com/watch?v=wjZofJX0v4M
tiktokenizer:https://tiktokenizer.vercel.app/
How Many R's in 'Strawberry':https://community.openai.com/t/incorrect-count-of-r-characters-in-the-word-strawberry/829618/6
what-are-generation-prompts:https://huggingface.co/docs/transformers/main/en/chat_templating#what-are-generation-prompts
Prompt Engineering: https://www.promptingguide.ai/zh
deepseek repo: https://huggingface.co/deepseek-ai/DeepSeek-R1/
DeepSeek API docs:https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
OpenAI SDK:https://github.com/openai/openai-python
MCP: https://modelcontextprotocol.io/
mcp directory:https://cursor.directory/mcp
cline:https://github.com/cline/cline/blob/main/src/core/prompts/system.ts
Anthropic Agent Guide:https://www.Anthropic.com/research/building-effective-agents
deepresearch:https://github.com/langchain-ai/ollama-deep-researcher
deepresearch:https://github.com/langchain-ai/open_deep_research
smolagents:https://huggingface.co/docs/smolagents/en/conceptual_guides/intro_agents
OpenAI Responses API migration:https://developers.OpenAI.com/api/docs/guides/migrate-to-responses
DeepSeek reasoning model:https://api-docs.deepseek.com/guides/reasoning_model
DeepSeek function calling:https://api-docs.deepseek.com/guides/function_calling
Anthropic MCP connector:https://platform.claude.com/docs/en/managed-agents/mcp-connector
smolagents secure code execution:https://huggingface.co/docs/smolagents/en/tutorials/secure_code_execution